ポッドキャスト収録終了から15分で編集済み音声ファイルを作る - 「趣味でOSSをやっている者だ」の場合
趣味でOSSをやっている者だ というポッドキャストを始めて1年が経った。そのノウハウを横展開して、ヘンリー社でもヘンリー理想駆動ラジオというポッドキャストを始め、運営に関わっている。
怠惰な自分でも続けられるように省力運営志向で、特に編集には時間をかけたくない。ただ、それなりの音声クオリティは保ちたい。それを自分なりにOKなラインになるように各種ツールを組み合わせて運用している。
ポッドキャストを始めてから大きくツール構成を変えたわけではなく、Ossan.fmの @nagayama さんに相談して教えてもらった内容をベースにしている。大感謝。その辺りの話は、1: 秋はポッドキャストの季節 (nagayama)、 2: 令和最新版ポッドキャストの始め方 (nagayama) でも話しているので興味があれば聞いてみて欲しい。
今は、収録を終えてからスムースにいけば15分程度で、公開用の音声ファイルを作成できている。その辺りの話を書いてみたい。マイクなどのハード周りの話は前回の、「リーズナブルに整えるオンラインミーティング向けマイク環境」で書いたので、今回は収録から音声ファイル作成までのソフトウェア関連の話が中心です。
大事なポイント
- 話者毎のマルチトラック収録
- 話し手毎に独立した音声ファイルを収録し、それを後で合成する
- Riverside で実現
- AI自動編集ツールへの丸投げ
- ノイズ除去やレベル調整など
- Auphonic が凄過ぎる!!!
Auphonicは、nagayamaさんに聞くまで知らなかったが、Rebuildでも使われている 、ポッドキャスト編集ではメジャーなツールのようだ。これがなかったら私もポッドキャストを続けられなかったと思う。
話者毎のマルチトラック収録 (Riverside)
使い慣れたGoogle MeetやZoomなどで収録する方法はお手軽だが、そのままだと単独音声ファイル取得のみで、話者毎に分離された音声ファイルが得られない。これは、その後の編集が不便になり、特に、話者毎に声の大きさの差が大きい場合に声の大きさを揃えるレベル調整がやりづらかったり、ノイズ除去を個別にかけづらいのが難点だ。なので、ここは最低限、話者毎に分離された音声ファイルを入手したい。
やる方法はいくつかあるが、私はそれができる収録ツールに丸投げしていて、それがRiverside。Ossanfmでも使われている。
良くあるオンラインミーティングツールのようにブラウザから利用でき、ゲストはユーザー登録せずとも招待リンクから参加できるので負担が少ない。収録ボタンを押して開始すれば、話者毎に音声が録音されてリアルタイムに非同期でアップロードされる。収録が終わったら、話者それぞれの音声ファイルをダウンロードできる。
話者毎にロスレス音源(wavファイル)が取得できるが、頭出し音源 (aligned audio) としても取得でき、途中参加者がいても編集しやすいのも嬉しいポイントだ。
注意事項
Riverside側の遅延や利用者側の環境の問題などによって動作不安定になったり、無料プランではマルチトラックのロスレス音源は取得できないなどの制約はあるが、特に気にはしていない。
動作が不安定になり利用者が途中で落ちた場合でも、復帰すればRiverside側が音声アップロードのレジューム含めて適切にハンドリングしてくれるので、今のところ大きな事故になったことはない。心配ならバックアップとして参加者それぞれが手元でQuicTimeなどでローカル録音するのが万全だとは思う。
あと、デフォルトではビデオも録画されて転送量が凄いことになるので、画面が必要ないなら音声のみ録音して転送する設定にすると良い。
プランについては素直に年間$180のStandardプランを契約している。ただ、現在はStandardプランは新規契約できず、年間$288(もしくは月間$29)のProプランがミニマムの有料プランになるので、個人では少し悩む金額感だ。ただ、ProプランだとAI編集機能などが使えるようなので、その機能次第ではAuphonicを使わずに済む可能性もあり検討の余地はあるかもしれない。
また、Spotifyでポッドキャストを配信している番組も多いが、RiversideはSpotifyと提携し、統合された収録ツールとして利用できる点でも有力な選択肢になる。
代替サービスやツール
同様のサービスではzencastrが古くからの定番で、RebuildはCleanfeedを使っているようだ。また、StreamYardを勉強会やイベント配信用に契約していて、それをポッドキャスト収録でも流用している企業もあるようです。
また、有力な変わり種として、CraigというDiscordボットを使う手もある。Discordの音声チャットにボットを招待して音声を録音してもらうものだ。これは無料でマルチトラック録音ができるので使っているポッドキャストも多い。例えば、Yokohama North AM や readline.fm など。
ちなみに、Zoomも参加者毎の音声を個別録音できるオプションがあることを、@tsueeemura さんに教えてもらいました。ロスレス音源ではないAACであることや、無料の場合には40分制限がかかるが、それを許容できるなら悪くない選択肢かも知れない。
また、CraigやZoomの場合はローカル録音された物がアップロードされるわけではなく、圧縮・伝送された音声をサーバーやボット側で録音する形式になるので、多少は音質が落ちていることは留意が必要だ。
何にせよ参加者毎にマルチトラック録音できてロスレスに近い音源が取得できれば、あとは使いやすいツールを使えば良い。それぞれが同時にローカル録音する方法もお手軽ではあるが、頭出しの手間が少しかかるし、録音ボタン押し忘れ等による録音失敗トラブルも聞くので注意。ローカル録音含めて冗長録音している番組もあるようで、ちゃんとやりたいならそうした方が良いのだとは思う。
AI自動編集ツールへの丸投げ (Auphonic)
とにかくAuphonicが素晴らしい。Auphoicは正確にはポストプロダクションツールで、音声ファイルを作る最後の工程を自動化してくれるツール。本来は収録した音声を手で編集した後に最後にかけるものだが、レベル調整、無音部分やノイズ、咳払い除去などを自動処理してくれるAI編集機能があり、私は自分で編集は基本行わず、横着してそれに丸投げするスタイルを取っている。
乱暴なスタイルだが、それで自分的には全然許容できる音質もののになっている。同様のスタイルを取るポッドキャストも増えてきている印象。
具体的には、Multitrack Productionの画面のフォームからRiversideで収録した音声ファイルを人数分アップロードし、設定のプリセットを選んでサブミットするだけで、しばらく待てば音声ファイルが書き出される。1時間分の収録音声の処理が順調に行けば10分程度で終わってしまう。
具体的なプリセット設定は以下のような具合。書き出しは96kpbsのモノラルのMP3にしている。モノラルなので各トラックの設定は同じにしている。
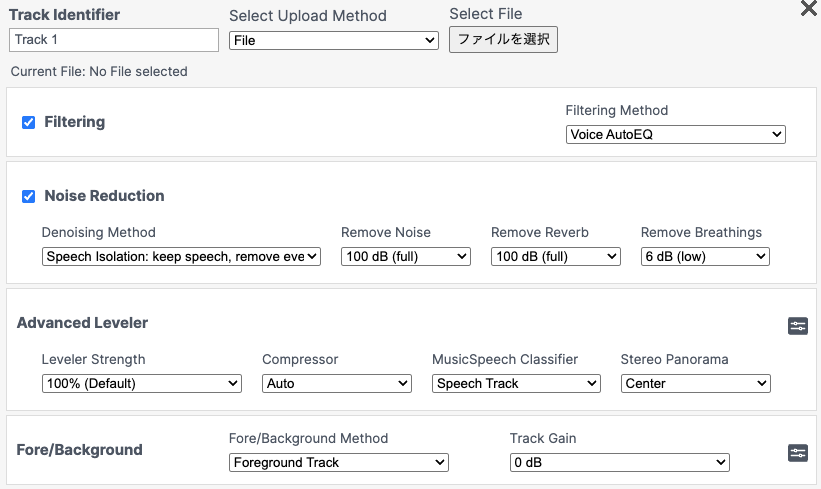
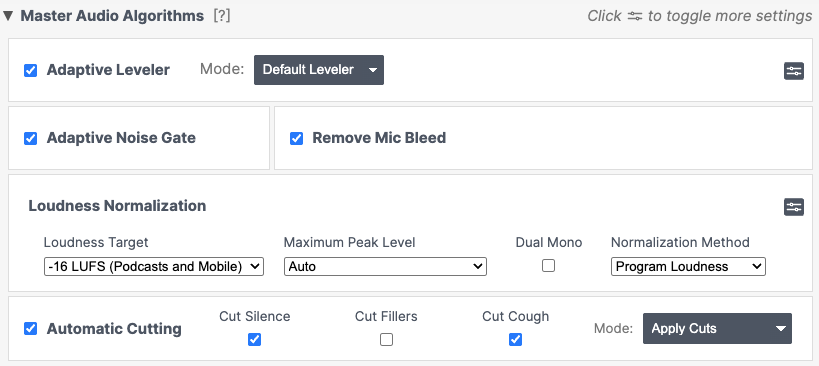
ちなみに、ファイル書き出し品質は年々向上傾向で、Podcast standardの統計を見ると、今は128kbpsのステレオが多数派になっているようだ。
wavをflacに変換してサイズを圧縮するtips
音声ファイルをAuphonicにアップロードする際に、wavファイルを直接アップロードすると、結構時間がかかることがあるので、ロスレス圧縮音源のflacに変換してからアップロードすることをお勧めする。声だけの音源だと5倍程度サイズが小さくなるので、比例してアップロード時間が短くなる。つまり1分が10秒そこそこになる。私は以下のような雑なシェルスクリプトでディレクトリ内のwavをflacに一括変換している。
#!/bin/sh
set -ex
for i in *.wav; do
ffmpeg -i "$i" "${i%.*}.flac"
rm "$i"
done
料金プラン
月々のプランよりも無期限の"One-Time Credits" をまとめて買っておく方が、趣味ポッドキャスターの場合はお得だと @nagayama さんに教えてもらって、100時間分を$150で購入した。月々のプランだと、一番安いSプランで月額$11。それで9時間分の処理ができるが、一ヶ月に9時間も収録しないのでワンタイムの方がお得になる。
まだ出来ていない活用
AuphonicにはAPIや、Google DriveやDropboxなどのクラウドストレージとの連携機能もあるため、その辺りを組み合わせたら、収録終了をトリガにしてプロダクション音源を自動的に書き出して配置してくれるなどもできそう。ただ、今の手動フローでも十分に短時間で済んでいるし、収録語に音源の微調整が必要になることもあるため、やっていない。
また、Intro/Outroを自動的に繋げてくれる機能は試したいとは思っている。特に、番組購読のお願いやお便りフォームの案内などは固定音声を作ってしまってoutroで繋げてしまえば良いよなーと思いつつ幾星霜。
その他のツール
手動での音声編集が必要になった場合 (ffmpeg, Audacity)
収録トラブルなどで、複数の音声ファイルを繋げたり重ね合わせたり、一部カットしたりする必要が出てきた場合には、機械的な処理であれば ffmpeg を使い、確認しながらのカット等が必要になれば、Audacity を使っている。無料で使える定番。
ffmpegはオプションが複雑で難解だが、今なら使い方をChatGPTに聞けば大体いい感じに教えてくれるので便利。Audacityは無料なのでありがたいが、Mac上で使う分にはちょっとUIに癖があるので、もう少し手ごろな良いツールがあれば乗り換えたいが、プロユースの物は高額だし複雑すぎて逆に使いこなせなさそうなので手を出していない。
ローカルでのノイズ除去 (krisp)
ポッドキャスト収録に限らず、オンラインミーティングなどでも活用できるので一応ローカルノイズ除去の krisp を契約している。年間$96。
据置のコンデンサマイクに切り替えて、打鍵ノイズなども少し気になったので、導入し始めたが、最近は各種オンラインミーティングツールにノイズ除去が搭載されることも多くなってきたので、必要なくなってきているかも。ノイズ除去が複数レイヤーで重複して施されて、薄っぺらい音声になったりしてそうだが、今のところ気にしていない。
AI文字おこし (Notta)
公開用の音声ファイルが出来た後、一応音声ファイルをひと通り聞いて内容確認しながらチャプター付けや公開用Show Notes作りをしている。それを楽にするために、AI文字起こしサービス Notta のプレミアムプランを契約している。年間14,220円。
公開音声をNotta上にアップロードして文字おこししてもらい、文字起こしを見ながら倍速再生で内容を確認している。文字起こしの精度はヒントなどをちゃんと与えているわけでもないのでそれほど高くはないが、文字起こしをクリックして再生位置ジャンプができたり、キーワードを拾ったりできて便利。
MP3へのチャプター付け自体は、拙作のポッドキャスト配信ツールである、podbard にその機能を持たせている。またその機能を切り出した別のOSSとしとして chapeというものがあり、これはvim等のエディタでポッドキャストの音声ファイルにチャプターやその他メタデータを付与できるので便利です。
ちなみに、連携しているLISTENの文字起こし精度がNottaとも遜色がなく、UI的にも文字起こしを確認しながらチャプター付けをするのにも向いていそうだが、公開前に内容確認をしたい関係でNottaを使っている。実はLISTENでも非公開音源の文字起こしができそうで、それをやりくりする方法もありそうだが、それは流石にabuseだと思うのでやらない。LISTENはLISTEN内でホストされている以外の連携ポッドキャストも無料で文字起こしできるのは大分太っ腹だと思う。
また、チャプター付けについては ForecastというMac用のツールもあり、これを使っている人もまま見ます。Overcast と開発元が同じなので信頼感はある。
まとめ
ということで、ポッドキャストの収録から編集済み音声ファイル作成までの流れをまとめてみた。ちょっとくらいの金額だったらお金を使って楽をする方針だけど、なんだかんだで積み重なって、この部分だけでも年間7万円くらいお金がかかっていることが判明してしまった。
気が向いたら、以下のようなことについてもまとめたい。
- ゲストアサインや収録の様子
- 配信プラットフォーム選定やポッドキャスト開始時にやった方が良いこと