2026-06-17 00:58
https://github.com/Songmu/OctoBiz
GitHub社はMona Sans というオープンソースのフォントを公開していて、社内で作られて公開されるプレゼンテーションはこのフォントが使われることが多い。ただ、このフォントには当然日本語のフォントが含まれておらず、プレゼンテーションを和訳する際には他のフォントを使わざるを得ず、テイストが変わってしまうのが気になっていた。
なので、このMona Sansと日本語フォントを合成し、日本語の資料に使うためのフォントを作った。合成する日本語フォントは、モリサワのユニバーサルデザインフォントのBIZ UDゴシック のプロポーショナル版のBIZ UDPゴシックを採用し、OctoBizと命名した。今後業務で使っていけると良いかなと思っている。
BIZ UDPゴシックは400(Regular)と700(Bold)の2種類を提供しているので、OctoBizもStaticフォントとしてその2種類を用意しています。GitHub Releases からダウンロードしても良いですし、Homebrewでインストールもできるようにもしました。
$ brew install Songmu/tap/octobiz
作ってみて、フォント周りの知識が少し増えたので面白かった。
インスパイア元
私は今は白源/HackGen というプログラミングフォントを使っているのですが、このフォント作者のyuru7さんが、BIZTER という合成フォントを作られていて、そのリポジトリ内の合成用スクリプトを流用させてもらいました。なので、アイデア・着想・手法すべてBIZTERから頂いています。ありがとうございます。
OctoBizのリポジトリはBIZTERのリポジトリを参考にしつつ、簡単な依存管理的な仕組みと、tagprによるリリースの自動化も実現できて満足している。Homebrewでのインストールも簡単にできて良かった。
余談
GitHubはMonaspace というプログラミングフォントも公開しているので、これもまた日本語フォントと合成してみようかと思っていたら、yuru7さんがすでにMoralerspace というフォントを作られていた。バリエーションも色々あって良い感じなので、プログラミングフォントはこちらに乗り換えようかと検討している。
感謝の意味も込め、yuru7さんにはGitHub Sponsor させてもらいました。ありがとうございます!
2026-04-19 15:32
注: 本記事は執筆時点(2026年4月)の情報をもとに書いています。実際のご利用にあたっては、公式ドキュメント等の最新情報を参照し、正確性を確認の上ご利用ください。
さて、axiosへの攻撃の件で、サプライチェーンアタックの恐ろしさを改めて感じさせられました。外部ライブラリを使う場合、基本的にはセキュリティ面も含めて最新バージョンを使いたいわけですが、その更新作業は脆弱性が入り込みやすいタイミングでもあるというジレンマがあるわけです。
なので、以下のようなポリシーとフローでの外部ライブラリ利用が現状の推奨要件と言えるでしょう。
基本は最新バージョンを使う
機能面、パフォーマンス、セキュリティ面でより良い
追随を怠ると更新が困難になり、新機能が使えないだけではなく、セキュリティリスクも高まる
ただし、新バージョンリリース直後ではなく、しばらくしてから最新版を適用する
最新バージョンに問題が無いか様子見をしてから入れるということ
特に最近は単なるバグや脆弱性だけではなくmalwareが仕込まれるケースが出てきた
検証してから最新バージョンに更新する
CIでテストが通るか・おかしな挙動が無いか確認してからコードベースに反映する
その後、開発者の手元、本番環境でも更新をおこなう
特に2点目が最近よく言われるようになってきたポイントです。"Minimum release age" や "cooldown" と言われる、リリースから一定の期間経過後に最新バージョンを入れるというものです。dependabotやrenovateなどの更新ツール、JavaScript周辺のパッケージマネージャーは一通りそのための機能をすでに備えています。
3点目の「検証してから最新バージョンに更新する」も簡単に書きましたが、厳密に考えると少し厄介です。検証時点でmalwareが混入する可能性があるからです。今回のaxiosの件もまさにそういうケースでした。
そう考えると先程の要件を一通り満たすためには以下のプラクティスが必要です。
自動的にバージョンアップが促されるワークフローを構築する
"Minimum release age" 設定ができるツールを利用する
秘匿情報にアクセスできない隔離された環境で新バージョンの検証を行う
これらをDependabotで実現する方法を紹介します。
Dependabotでの実践例
Dependabotを導入し、自動的にバージョンアップが促されるようにする
Dependabotは依存ライブラリ更新のワークフローを構築するGitHub組み込みの機能であり、無償で利用できます。定期的に依存関係の更新をチェックし、PRを起票してくれます。
以下のようなYAML設定を配置するだけで利用を開始できます。
# .github/dependabot.yml
version: 2
updates:
- package-ecosystem: "npm"
directory: "/"
schedule:
interval: "weekly"
cooldown:
default-days: 7
上記はnpmに対して週次でチェックをするシンプルな設定例ですが、チェック頻度の変更、他のパッケージシステムでの利用、グルーピング設定なども出来ます。詳しくはドキュメントを参照ください。
Dependabot quickstart guide - GitHub Docs
cooldown項目でminimum release ageを設定する
先のYAMLの例の中にも書いていましたが、cooldown項目で、リリースから一定期間経過してから最新バージョンを入れるようにできます。これも細かい設定が可能で、例えば、一部のライブラリは除外したり、上がったバージョンがメジャーバージョンかマイナーかで期間を変えたりもできます。これもドキュメントを参照してください。
Dependabot options reference - GitHub Docs
dependabotが起票したpull request上で検証を行う
dependabotはpull requestの形でバージョンアップの提案をしてくれます。ですので、そのPR上のGitHub ActionsのCIワークフローで検証を行えます。
dependabotはリポジトリシークレットにアクセスできない
ここで嬉しいのは、このPR上のワークフローは外部のforkリポジトリからのPRと似たような権限モデルで動くことです。具体的にはリポジトリシークレットなどにはアクセスできないため、そこからトークン等が漏洩する心配はありません。GITHUB_TOKEN もデフォルトではread-onlyになります。
Dependabot が更新する依存パッケージには信頼できないコードが含まれる可能性があるため、fork からの PR と同等に扱うということなのでしょう。その点では、package.json などのバージョンファイルを開発者が更新してPRを起票するより、dependabotに任せた方が安全とも言えます。詳しくは以下を参照してください。
Troubleshooting Dependabot on GitHub Actions - GitHub Docs
github actions workflow runs that are triggered by dependabot from push, pull_request, pull_request_review, or pull_request_review_comment events are treated as if they were opened from a repository fork.
Dependency reviewと組み合わせる
パブリックリポジトリや、GitHub Advanced Security (GHAS) の契約がある場合、dependency reviewを使えば、PR上の依存関係変更に対するレビューを追加でおこなえます。具体的にはGitHub Advisory Database を参照し、依存関係に脆弱性がないかをチェックしてくれます。これもPR上で動くワークフローで実行できるため、問題がある場合に変更をブロックできます。
# .github/workflows/dependency-review.yml
name: Dependency Review
on: [pull_request]
permissions:
contents: read
jobs:
dependency-review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
persist-credentials: false
- uses: actions/dependency-review-action@v4
Dependency reviewには、自分たちのコードベースに望ましくないライセンスのコードの混入を防ぐ機能などもあります。OSSだと無償なので積極的に使うと良いでしょう。詳しくはドキュメントを参照してください。
About dependency review - GitHub Docs
ローカルマシンのリスク軽減
ここまで説明した通り、依存ライブラリの安全性を確認してから、各開発者のローカルマシンに展開していくのが安全なフローです。
ただ、開発者やローカルのコーディングエージェントがこのフローを守らず手元でうっかりアップデートしてしまう場合には無力です。それを防ぐためにはやはり、.npmrc など、手元の開発環境の設定も合わせてしっかりやることも重要です。
また、AIコーディングエージェントはかなり気軽にnpm install や pip install 等を実行するため、変なサイトに情報を流さないようにサンドボックス機能があるとやはり嬉しいところです。先日紹介したfenceのようなサンドボックスツールを活用するのも一つの方法でしょう。
コードベース窃取等の外部送信への対策
どこまで気にするかという話もありますが、今回のaxiosのようにシークレットを狙うのではなく、コードベースを丸ごと盗もうとするようなmalwareの場合には、上記の方法だけでは不十分です。ただ、こういった無差別型の攻撃の場合、攻撃者はコードベースよりシークレットを窃取しようとすることが多いため、気にするべきリスクの優先順位としては低くはなります。
ただ、その辺りも含めて外部への情報送信リスクを懸念するようであれば、CI環境で怪しいサイトへの通信をブロックすることでリスクを低減できます。GitHub ActionsのGitHub-hosted runnerの場合、etc/hosts ファイルのプロビジョニングで怪しいサイトへの通信はブロックする
更に追加で自分たちで監査したり、許可・拒否リストの管理をしたいケースでは、サードパーティのStepSecurityのHarden-Runner などの導入が手軽ですが、プライベートリポジトリの場合は有料です。他には、GitHub Actionsからの外部通信をAzure private networking経由にする方法 やSelf-hosted runner で自分たちでしっかりネットワーク制限をかける方法もありますが、運用コストは上がります。
これについての本命として、GitHubも最近発表したセキュリティロードマップの中で、"Native egress firewall for GitHub-hosted runners" を年内くらいのターゲットで提供予定であることを公表しているので、期待したいところです。それ以外の下記の記事に記載されているロードマップ機能にはいずれも期待しています。
What's coming to our GitHub Actions 2026 security roadmap
2026-04-11 21:20
AI Agentも賢くなってきたとはいえ、ローカルで何をしでかすかわからない怖さは拭いきれない。かと言って、細かく認可を与えるのもめんどいし、ザルな見過ごしも起こりやすくなって危ないので、できればファイル・ネットワークアクセス、コマンド実行等に適切に制限をかけたサンドボックス環境で放し飼いにしたい。
CLIとして動かすAI Agentの場合、引数に指定したコマンドをサンドボックス内で動かすコマンドラッパーがあると嬉しい。自作しようかと思っていたが fence というツールがまさしくそれだったので、これを使うことにした。Goで書かれていて、macOSとLinuxをサポートしている。早速、GitHub Copilot CLIでも利用しやすいようにpull requestを送って 、取り込んでもらった。
使い方
使い方は簡単で fence コマンドの引数にサンドボックス内で動かしたいコマンド、今回のユースケースであればAI AgentのCLIを指定するだけだ。
$ fence copilot
$ fence claude
ただ、最初は外部へのネットワークアクセスが遮断されているので最低限の設定ファイルは必要だ。これも簡単で、fence config init とすれば ~/.config/fence/fence.json に初期設定を書き込んでくれる。初期設定は以下のように簡素だ。
// Starter config generated by `fence config init`; this file extends "code".
// Rules from "code" are inherited and not shown below.
// Add your project-specific overrides in this file.
// Run `fence --list-templates` to see available templates.
// Configuration reference: https://github.com/Use-Tusk/fence/blob/main/docs/configuration.md
{
"extends": "code"
}
これは、code というCoding Agent用のビルトインテンプレートを継承している。このテンプレートの中身は以下から参照可能だ。特定のAI関係のドメインのみにアクセス許可を与え、ローカルの秘匿ファイルへのアクセスや git push などのコマンドは拒否するようになっている。実際の項目ごとの設定内容は fence config show で確認できる。ここから適宜調整すると良いでしょう。
https://github.com/Use-Tusk/fence/blob/main/internal/templates/code.json
動作確認とデバッグログ
fence の中でAI Agentを動かしていると、ファイルやサイトアクセスのブロック起因で意図しない挙動になることがある。それを確認するために、--monitor と --debug オプションをつけて起動すると、モニターログが出力され、実際にブロックされたファイルやサイトを確認できる。ログは標準エラー出力に出るので、ファイルにリダイレクトして、tail で確認するとよいでしょう。ブロック状況を確認して、必要に応じて許可設定を追加すると良いでしょう。
$ fence --debug --monitor -- copilot 2>> .fence-monitor.log
$ tail -f .fence-monitor.log
Appendix
同種のソフトウェア
srt (3.7k stars): Anthropic社が開発しているTypeScript製のサンドボックスツール。ライブラリとしてClaude Code内部でも使われているnono (1.8k stars): Rust製のサンドボックスツールcage (100 stars): 日本の方が作られたGo製のツールで日本の技術記事での事例紹介が散見される。ファイルシステムのサンドボックス化のみ提供
fence は600 starsなので、srtやnonoほどではないが、十分に信用がおけると判断し、Go製であることが私にとっては好ましいので採用することにした。
ちなみに、もともとはcageの存在だけ認識していて、そのネットワーク版を作ろうと思ってプロキシ設計までやっていたのだけど、調べたら同種のソフトウェアが流石にあるということが分かったのでそれに乗ることにしたというのがある。ラッパーコマンド自身がプロキシになってそれ経由の通信しか通さなくするというアーキテクチャは面白いので作ってみたかったが、こういうツールは既存の成熟したものを使う方が安心。
いずれのツールでもmacOSではApple SeatbeltというOS組み込みのサンドボックスを使っている。非推奨な機能らしいが、CLIでは代替手段が提供されてておらず、多くのツール内で使われているため、もはや廃止は難しそうになっているようだ。
Linuxではsrtとfenceはbubblewrap , nonoとcageはLandlock を使っている。
この辺りは以下の記事が参考になります。
Claude Code組み込みのサンドボックス機能を使えばよいのでは?
これまでの説明どおり、内部的には同様のことをしているのでそれで良いと思います。まあ、こういうのは別の専用のツールに分かれていた方が責務分離的に安心だし、細かい設定も可能だというのはあるでしょう。
というより、私が主に使っているGitHub Copilot CLIがまだサンドボックス機能が無いので、使っているというのが現実でもあります…。Copilot CLIのissueでも実装も望まれているので、そのうち機能追加されるとは思いますが、早めの対応を期待したいところです。
Add sandbox mode to restrict Copilot CLI file access to a specified working directory · Issue #892 · github/copilot-cli
2026-03-26 00:03
Markdownの中に 「@copilot 〇〇について調べて」みたいなプロンプトを書けば、コーディングエージェントが自動でそれを認識して非同期で動作してくれると嬉しい。なので、そういうツールを作った。それが ghsummon。その名の通り、手元からAI Agentを召喚するツールで、GitHub Actions上で動かす。
https://github.com/Songmu/ghsummon
@copilotで始まる行がGitHub上にpushされると、pull requestが自動で作成される。該当行をプロンプトとして認識し、GitHub Actions上でCopilot coding agentが動き、pull request上でファイルを編集してくれるという仕組みだ。
動作イメージのpull requestがこちら 。"Who is @Songmu" というプロンプトに対して、GitHub Actionsが動き、README.mdを編集してくれている。
これは、GitHub Copilot coding agent というGitHub Actions上でCoding Agentを動かす機能を単に利用しているだけなのですが、ファイルにプロンプトを書き込んでpushするだけでAIにタスクを依頼できるのは便利。
私の利用法
私は日常のメモやドキュメントを Obsidian で書き、Gitプラグインで定期的にGitHubにpushしている。なので、プロンプトをファイルに書いておけば、定期pushのタイミングで自動的にCoding agentが動き始めてくれるようになり早速捗っている。
GitHub Copilot coding agentではカスタムエージェントも利用でき、サブエージェントも動作できる。なので、調査タスクなどを任せる場合、検証・再調査ループを回してくれるリサーチ用のカスタムエージェントを定義しておけば、かなり精度の高いレポートを生成してくれる。
pull request上で生成された内容を確認できるのも嬉しい。何か追加調査や調整してもらいたかったら、pull requestのコメント上で @copilot 〇〇について最新の情報を調べて追記して 指示を与えれば、さらに調査を続けて内容を更新してくれる。内容を確認してからマージすればよいので、調査をやらせっぱなしにして内容を読まないで腐らせてしまうことが減るのも嬉しいポイントだ。
使い方
リポジトリに以下のようなGitHub Actionsのワークフローファイルを置けばよい。あとはリポジトリ内でCopilot coding agentを動かすために、 copilot-setup-steps.yml というファイルも置く必要がある。詳細はREADMEを参照して欲しい。
name: ghsummon
on:
push:
branches: [main]
paths: ['**.md']
permissions:
contents: write
pull-requests: write
jobs:
research:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v5
with:
persist-credentials: false
- uses: Songmu/ghsummon@v0
with:
token: ${{ secrets.GHSUMMON_TOKEN }}
また、APIでpull requestにcoding agentをアサインするために、PAT(Personal Access Token)を作る必要があるのが現状ちょっと悩ましいポイントではあります。
注意点
GitHub Copilot coding agentを動かすので、GitHub Actionsの実行時間やCopilotのプレミアムリクエストを消費します。
同じファイルに対してはpull requestとリモートブランチが生きている限り重複実行はされません。なので、逆に該当pull requestをマージなり閉じたりしたあとは、ブランチを削除しないと、そのファイルにプロンプトを書いてpushしても反応してくれないので注意が必要です。
今後の展望
今は、Markdownファイルにプロンプトを書く私のユースケースに最適化されているが、コードファイルへのプロンプトもサポートできると嬉しいかも知れない。例えば // @copilot ここ実装して みたいな具合。
また、現状は、pushされたコミットから新しいブランチを切るようになっているが、ブランチを維持してほしい場合もあるだろう。あとは、 @copilot 以外のエージェントも呼び出せるとかも。
そのあたりはissueに積んでありますが、使ってみて要望などがあればご意見いただけると嬉しいです。
2026-03-17 02:23
CLIをAI AgentフレンドリーにするためにAgent Skills があると嬉しい。Agent Skillsは絶賛リポジトリ で協議されているが、オープンスタンダードであり、各ベンダーがそれなりに足並みをそろえながら仕様がアップデートされている。フロントマッター付きのSKILL.md というMarkdownを .agents/skills/skill-name/SKILL.md のような場所に配置することで、Agentにskillを備えさせられる。配置場所も各ベンダー独自の場所もあったが、最近は主要ベンダーが .agents/skills もサポートし、その点では安定した。
OSS作者もリポジトリルートに skills/ ディレクトリを掘り、その中にAgent Skillsを置く人も増えてきた。そうしておけば、skills add などのインストーラーでスキルを導入しやすくなる。
そこで思いついたのがCLI自体にもAgent Skillsのインストーラーをバンドルしてしまう方法だ。mycli skills install などとすればCLIが自分のスキルをインストールしてくれると嬉しい。
Goの場合、embed パッケージがあり、リポジトリ内の skills/ ディレクトリを簡単にコードに埋め込むことができる。これを利用すれば簡単にインストーラーを作れるはずだ。バージョン情報も含めればスキルの更新も管理できるし、CLIとAgent Skillsのバージョンの食い違いによる問題も減らせる。
そこで作ったのが github.com/Songmu/skillsmith である。これを使えば、Go製の任意のCLIにサブコマンド skills を生やせる。以下のようなコマンドが利用できるようになるのだ。
mytool skills list # List embedded skills
mytool skills install # Install skills to ~/.agents/skills
mytool skills update # Update skills to newer versions
mytool skills reinstall # Reinstall all managed skills
mytool skills uninstall # Remove managed skills
mytool skills status # Show install status and version diff
組み込むのも簡単だ。以下は最小の組み込み例だが雰囲気は伝わるだろう。実際に、最近作った fmd2json や gitrail といったツールに組み込んでいるので、興味がある人はそちらも参考にして欲しい。
import (
"context"
"embed"
"log"
"github.com/Songmu/skillsmith"
)
//go:embed skills
var skillsFS embed.FS
func run(ctx context.Context, args []string) error {
if len(args) > 0 && args[0] == "skills" {
s, err := skillsmith.New("mytool", version, skillsFS)
if err != nil {
log.Fatal(err)
}
return s.Run(ctx, args[1:])
}
// ... existing command handling
return nil
}
特定のCLIライブラリに依存しない形で作っているため、逆に任意のCLIライブラリで作られたCLIにも組み込みやすいはずだ。
とは言え、まだまだ出来たばかりで発展途上だし、既存のメジャーなCLIライブラリの cobra や urfave/cli, kong などに組み込みやすいように、アダプターも用意したいとは思っている。ニッチなツールだが是非組み込んでみてフィードバックいただけると嬉しい。
ちなみに、CLI用のAgent Skillsを作るに当たっては、まずCLIの出力をndjsonにして、そのJSON SchemaをSKILL.mdに書いておくとAI Friendlyかなと思い、上記の2ツールはそのようにしてみた。
2026-02-26 01:58
開示ブームに乗り遅れたが、去年末から今年頭にかけてアップデートがあったので記録しておく。ものぐさなので、割と古いままだったりデフォルト厨寄りだったりするのだが、AIコーディングの流れもあり、多少は新しめのものも導入した。
OS: Mac
長く惰性で使っている。バックアップや他のスマートフォンやタブレットとの連携や、ファミリーアカウントなどの兼ね合いもあって、お金はかかるがAppleプラットフォームにどっぷりになっている。
dotfiles管理: 自前リポジトリ管理
https://github.com/Songmu/dotfiles
去年末に業務Macの設定する時に、リポジトリcloneしてリポジトリ内のsymlinkを適当に張るスクリプトを動かしたら大体動いたので、それで満足して良いかとなっている。
chezmoiへの乗せ変えを検討したが、dotfileはPC設定の初期にやることなのでその為に独自ツールが必要なのもイマイチだな考えて辞めた。ファイルのネーミングルールとかもちょっと余り好きではなかった。
生の設定ファイルを管理してsymlinkを張る方が単純でデバッグも容易。コーディングエージェントと一緒にデバッグもしてもらいやすい利点もある。
ただ、.ssh とかシークレット関連の管理は余りちゃんとやれてないのでその辺りは再考の余地があるがお茶を濁している。
エディタ: vim
neovimではない。プラグイン管理はvim-plug。
コーディングエージェント: GitHub Copilot
最近はGitHub Copilot CLIの開発が活発でターミナル上の体験も良くなったので、Claude Code MAXを使う必要もなくなった。CLIでプラン作って、シームレスにCopilot Coding Agentに切り替えてpull request上で作業してもらえのは体験が良い。
ターミナルエミュレータ: Ghostty
2024年にTerminal.appからWezTermに乗り換えていたのだが、Ghosttyに今年から乗り換えた。単にMitchell Hashimotoファンボだから。タブや画面分割はターミナルマルチプレクサに任せる主義で、別にターミナル固有の機能は使っていないので、乗り換えは楽。
シェル: zsh
あまり独自の .zshrc を太らせたくもないので、zplug でプラグインマネジメントしている。
ターミナルマルチプレクサ: tmux
ついにGNU Screenからtmuxに乗り換えた。流石にAI Agent周りのエコシステムを考えた時にWindowやペインを跨いだ制御がやりやすいtmuxの方が良いと判断した。
GNU Screenでやりくりするのも結構楽しかったし、2024年にWezTermを導入したのも、GNU Screen 5.0で20年ぶりにメジャーアップデートしてtrue color対応したのがきっかけだったりするので、最近の僕の開発環境刷新の契機にもなっている。
ランチャー: Spotlight
Alfredを買っていた時期もあったが、長らくSpotlight。最近だとアクション機能も追加されたし、Automatorとかと組み合わせて色々できそう。とは言え特にカスタマイズはしていない。
フォント: HackGen
https://github.com/yuru7/HackGen
ブラウザ: Choosy, Google Chrome
プロファイル切り替えや固有アプリで開く等の制御をするためにスイッチャーの Choosy をデフォルトブラウザにしている。実際に使っているブラウザは主にGoogle Chrome。
Choosyは開くアプリやプロファイルのルール設定を以前は頑張っていたが、特に頑張らずにポップアップから選ぶので全然困らないことに最近気付いた。
ノートテイキング: Obsidian
欠かせない。昔はターミナルが一番開いている時間が長かったが今はObsidianが一番長いと思う。バックアップはgitプラグインでGitHubとDropboxに同期している。
タスク管理: TaskMD Shelf, Obsidian
GitHub - Songmu/TaskMD-Shelf での管理が続いている。Obsidianでの管理と相性が良い。もっとAI支援してもらっても良いと思っているがまだできていない。
キーボード: MD770 JP 静音赤軸
いわゆる分割キーボード。特にカスタマイズとかなく吊るしで不自由なく使えるので長らく愛用している。外付けキーボードを使わないでMacbook Airのキーボードをそのまま使うこともある。
クラウドストレージ: Dropbox
周りに使う人は減った気がするが、Dropboxを引き続き使っている。メモや書類などはGitHub上置いている。なんだかんだでファイルが手元にすぐに持ってこられる安心感がある。旧世代っぽい…。あとは、iCloudをファミリー契約している。
日本語入力: Google日本語入力 or かわせみ
プライベートではかわせみを購入していて、業務用の端末にはGoogle日本語入力を入れている。かわせみ用の辞書を色々作りたいと思っているがやっていない。
Mac Mouse Fix
トラックパッドとマウスホイールの方向を逆にできるので便利。長らくScroll Reverserを使っていたが、マウス関連の設定も色々出来るので乗り換えた。
Window Manager
特にこれまで使ってこなかったが、typester/yashiki が気になっている。
Git関連
ghq
メモなど含め、開発以外でも様々なリソースをGitHub上で管理しているので、それらがghq get ですぐに手元に持ってこられるのは便利。GitHub社自体も多くのリソースをGitHubで管理しているのでそれらをパッと取得できるのも便利ですね。
TUIクライアント: tig
複雑なTUIクライアントは使っていないが、tigだけは手放せない感じになっている。主にgit log 代替として履歴を手元で確認するために使っているくらい。
diff表示: delta
git-diff-highlight から乗り換えてみた。とは言え、tig内部でgit-diff-highlightを使う設定を残してあるので、git-diff-highlight もまだ併用している。tigとdeltaの連携issue もあるが、難航しているようだ。
CLI
インタラクティブフィルタ: peco
fzfに乗り換えようかとも思ったが特に困っていないし、愛着もあるのでpecoを使っている。と思ったら、最近約3年ぶりに v0.6.0 がリリースされたので歓喜。軽快に動いている。
検索: ag
Ackからagに乗り換えたのがいつかもう覚えていない。今だとrgを使っている人が多いと思うけど、agはタイプしやすい…。rgのaliasをagにするという手もあるとは思っているが、それはちょっとagを蔑ろにしている感じがするのでやっていない。
2025-12-31 23:17
今年は変な年だった。激しめのイベントが立て続けに起きた。良いことも悪いことが入り交じっていて、自分で撒いた種で自業自得なモノも多いが、ちょっと精神的に疲れた感じもあった。とは言え、色々好きにできて良い経験になったし、総じて面白い1年だったし、僕らしいふらふらした1年だったとも言える。
フリーランスとして独立
4月からフリーランスになった。(その後12月にフルタイムに戻った)
フェロー就任と独立のお知らせ | おそらくはそれさえも平凡な日々
所属していたヘンリー社からフェロー就任と言う提案をもらい、業務委託で仕事を発注してもらえたので、フリーランス移行の形としてはやりやすくてありがたかった。その後、おかげさまで、何社からか引き有りもあり、仕事をいただくこともできた。
ある程度、フリーランスのITコンサルタントとしてやれそうな感触は得られたが、もともと仕事を積極的に受けてはいなかったのと、後述の状況もあり、あまりフリーランスとして生きていけるという手応えを感じるまでには至らなかった。やはりフリーでやってる人はスゴいと改めて感じた。
母親の死
フリーランス初日の4/1の深夜に母親が他界した。親族から連絡があり、病院に駆けつけた時は既に息を引き取っていた。本当に晴天の霹靂だった。40代前半(当時)にして両親がいなくなってしまうのは流石にちょっと早い。
実家の自宅での突然死だったので「変死」扱いとなるらしく、深夜中に葬儀場を手配する必要があると共に、その後、実家での警察の調査と聞き込みに対応する必要があった。
喪主を務める必要があったものの何をすれば良いか皆目分からなかったが、ChatGPTが役に立った。病院での待ち時間や警察の調査の合間にChatGPTに色々聞きながら裏取りをするなどしていた。心を落ち着ける効果もあったと思う。
葬儀、各種手続き、相続など、とにかくやることが細々あり、それからしばらく奔走していた。良いのか悪いのかフリーランスだったので徹底的に片づけることができた。逆に、会社員だったら収入はキープできるメリットはあったと思う。フリーランスは幾らでも仕事をしない選択肢を取れてしまう。
相続周りはとにかく司法書士さんが頼りになり、丸っとお願いできて良かった。複雑な部分があったのだが、初回打ち合わせに必要そうな書類を一切合切持って行ったら、完璧に把握してくれて、後はお任せできたのでかなりありがたかった。
遺産分割協議書が4月中に用意できたのはかなりスムースだったと思う。ただ、その後諸々が完了するまでには6月中旬までかかった。遺産分割協議書の効力は強いものの原本しか効力を発揮しないので、法務局以外にも金融機関など様々なところに原本を持っていく必要があって大変だった。
ちなみに、とある金融機関の解約の為に必須書類ではない遺産分割協議書のコピーを念の為持っていったら薮蛇になったりした。「原本を見せて下さい」となったが、原本は司法書士に別の手続きのために預けていたので見せられず、受理してもらえなかった。後日改めて来行する羽目になったが、平日昼間にそんなに何度も地方の銀行に足を運ぶなど会社勤めだとなかなかできないし、それも数十円しか残ってないような口座に対してやるのは割に合わないので、そりゃ放置が正解だし休眠口座が増えるわ、となった。
とにかく、自分の手元に1葉しかない遺産分割協議書をリレーするのは効率が悪過ぎるので、デジタル化されてマイナンバーカードとかでロングタームな電子署名ができるようになって欲しいと思った。
母親の携帯電話を解約時には案の定無駄な付帯サービスがついていた。自宅にWifiもあるのにsim契約付きのタブレットを購入していたり、キャリア決済で色々なサブスクを契約していたりなど。しかも、外部サービスのサブスクは、キャリアの店舗では解約できず、それぞれのサービスで解約手続きが必要とのこと。クレカみたいな支払手段の提供だと考えればそういう理屈かも知れないが、店頭でサブスク案内しておいてそれはひどいとは思う。それらは諦めて放置することにした。実際「携帯電話契約が止まればキャリア決済も止まるので自動解約になるはずです」という案内をキャリアの人にされた。それもどうかと思う。
ちなみに、同様にクレジットカードを解約したときには「解約後も公共料金などはオーソリ(決済)が通ることがあるので、そうなったら後日請求書が届くのでお支払い下さい」と言われた。確かにライフライン系が突然止まったりしたら困るとは思うが、そういうこともあるのかと驚いた。
とにかく、悲しむ暇もないほど慌ただしかった。6月に「あー、今週は死後事務のことを何も考えなかったな」と感じた週があり、その時にやっと一段落した感があった。それまでは、マインドシェアの大半を死後事務に持っていかれていた
多少複雑な状況はあったものの、ステークホルダーは限定的で連絡に困ることもなく、揉めたりすることもなかったのでスムースではあったとは思う。それでも色々大変だった。
Obsidianによるタスク管理とTaskMD Shelf
この死後事務関連で出てくる色々なタスクをObsidianで管理しており、その中でタスク管理をかなり洗練させることができた。その方法を整理した手法がTaskMD Shelf である。
TaskMD Shelf - 積極的棚上げを由とする怠惰なタスク管理 | おそらくはそれさえも平凡な日々
今でもこの方法でタスク管理をしていて、かなり効果を発揮している。AI支援などはまでできる余地があるので、今後も改善を続けていきたい。
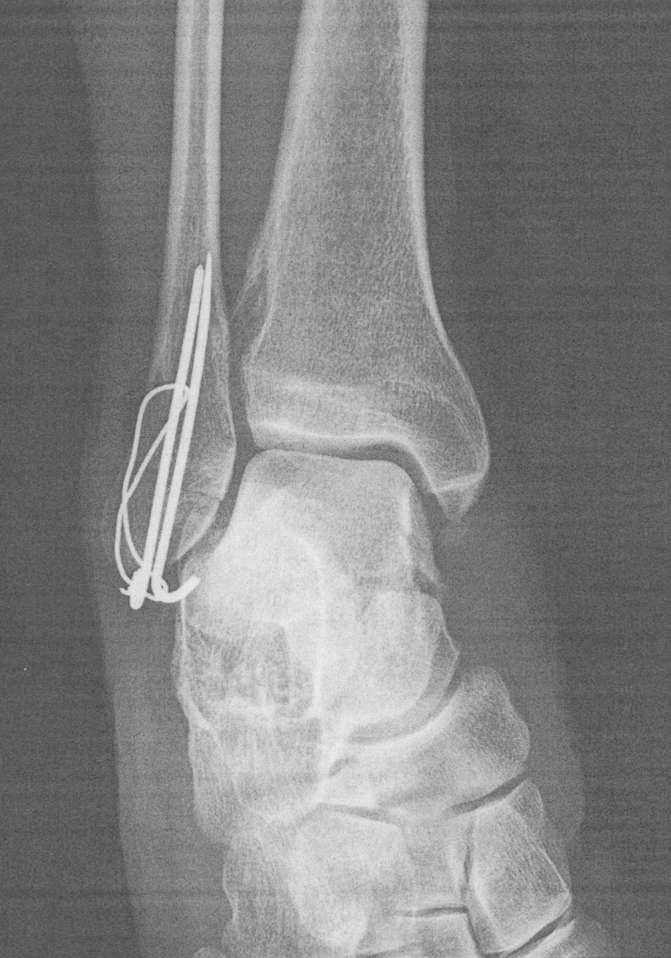
右足首骨折
7月末に右足首を骨折した。渋谷で飲んでいた時に、お店の中の階段で足を踏み外して足首を捻って折った。
割と複雑な折れ方をしていたので紹介状が2回出た。結局、自宅から少し離れた病院に入院して手術を受けたが、前住んでいた家の近くの病院で、何ならそこで10年以上前に鼻の手術も受けた 病院でもあったので縁を感じた。以下のような感じで繋げてもらった。
月曜の夜に折って金曜日に手術だったので少し時間がかかったが、足の専門医は少ないらしく、良い医師がいる病院に紹介してもらえたのは良かった。
ちなみに、骨折が判明して、まだ病院が見つかっていない最中にtwadaさんとポッドキャストを収録していた 。これは絶対に収録したかったので敢行できて良かったし、おかげ様で一番再生された回にもなっている。
閑話休題。足首は厄介な折れ方をしていたようで最初かかったクリニックでは「後遺症は残ると思います」と言われて少し凹んだが、今は一応完治扱いではあって日常生活や多少の運動には支障はない。まだ、ピンが入ったままなので来年それを抜く手術を受ける予定。
違和感や動きの渋さはあるが仕方ない。自覚は無かったが以前同じ足首の内側を骨折していた形跡があり、それが変なくっつき方をしていたと指摘を受けた。大学生の頃にやらかした身に覚えが少しあり、確かに右足が突っかかりやすい感じは常々あったので、遅かれ早かれこうなる運命だったのかも知れない。
1週間程入院したが、本やマンガを読んだりできてゆっくりできて良かった部分もあった。とは言え、家族や親族には大分迷惑をかけたし、大分助けられた。一人だったら大変だった。
Vibe Codingとk1LoW/deck
とにかく、Vibe Codingが一気に来た一年だった。AI周りについては、Cursor, Devin, Clineなどは静観していたが、6月にClaude Code Maxが出たタイミングで契約して、そこでVibe Codingの何たるかの感覚が掴めた。丁度よいタイミングだったように思う。「AI無職」という言葉も嘯かれていたが、奇しくもそんな感じでフリーランスに僕もなっていた。
k1LoW/deck の開発の中でもかなり活用できたし、その後でAIが作った負債を自分で綺麗にしたりチューニングするフェーズも味わえたので、AIの向き不向きだったり、AIにがっつり書かせたコードをどのように継続メンテナンスしていくか、みたいなところを早めに経験できたのは良かった。
k1LoW/deck のコミッターになった | おそらくはそれさえも平凡な日々
YAPC::Fukuokaでの発表の他にもdeckを使って良い発表ができたのは良かった。
ポッドキャストが続いた
趣味でOSSをやっている者だ も一年間続けることができた。ゲストの打診をした人達が快諾してくれるのが続けられている理由だと思っていて、ありがたい。
また、リリースフローをとにかく簡単にして最初から整えたことや、録って則リリースではなく、毎週リリースにしていることがリズムを保てて良いと感じている。
ありがたいことに、Spotify上では累計1.5万再生と500人以上のフォロワーが付いている。他の媒体は細かく調べていないが、あまり数字にこだわらずに続けているのが逆に良いと思っている。
また、LISTENを中心に、ポッドキャスターの輪が広がったのも面白かった。
町田.pmをリブートした
町田.pm をリブートして、年末まで活動を続けることができた。隔月の土曜日開催のもくもく会形式という、これも負担の少ない形で始めたのが継続できた理由だと思っている。毎回人も集まって、いい感じに入れ替わりもあったりするのも嬉しい。
来年も続けて行きたい。
GitHub
GitHubに入社した。8月末くらいから選考を受けており、選考自体はスムースだったのだけど、色々本決まりするのに時間がかかり、12月16日(火) という不思議なタイミングで入社となった。
年内はオンボーディングコンテンツや、各種手続を落ち着いてこなせたので、来年からはキリ良く働いて行く感じになりそう。
GitHub Japanに入社しました | おそらくはそれさえも平凡な日々
文筆業
「本を書いている」と公言しているが、進捗は悪い。来年巻き返して何とかしたい。担当の方はめっちゃ辛抱強く付き合ってくれているので応えたい気持ちはある。
STREET FIGHTER 6
今年の頭から始めて、やったりやらなかったりだったが、10月にジュリでマスターに到達できた。
死後事務の時は何もする気が起きなかったので、その分SF6が捗った。良い気分転換や救いにもなった。骨折の手術の退院後の療養期間も結構プレイした。
のめり込んで熱中していると言う感じまでは行っていないようにも思うが、マスターまでやったし、まだまだこれから感もあるので、なんだかんだでハマっているのだと思う。あと、やっぱ自分でやるとeSports観戦が楽しくなる。
来年は知り合いと対戦したりとか、大会出たりとかも機会があればやってみたい。周りにそれなりにやっている人がいるようなので。
2025-12-16 23:39
しばらくフリーランスとしてフラフラしていましたが、縁とタイミングが合って、12/16付でGitHub Japan にシニアソリューションエンジニアとして入社しました。開発職ではなく技術営業職で、担当は主にエンプラ領域の予定です。
GitHubが好き
「SongmuさんてGitHub好きですよね」
Mackerel のプロダクトマネージャーをやっていた頃、一緒に事業を手がけていたビジネスマネージャーのnkako さんにそう言われたことを覚えています。これは「そういうふうに見えているのか」という気付きを与えてくれました。GitHubはもちろん嫌いではありませんでしたが日常的に使うサービスなので、好き嫌いはそこまで意識してはいませんでした。
ただ、MackerelのPdM時代はかなりGitHubを意識していた事は確かです。個人の道具としても仕事でも使えることや使いたくなるサービスであることを目指していて、それらはかなりGitHubから影響を受けていました。
その後GitHub Actionsが出てきて、このブログやポッドキャスト のリリースフローを整えたりする中で、GitHubは以前にも増して私の人生にも欠かせないサービスとなりました。今、一番好きなWebサービスは何かと問われたらGitHubと答えるでしょう。
外資のIC再チャレンジと大企業
フリーランス継続の可能性も高かったのですが、外資のIC職で不完全燃焼だった経験 から、英語も使える環境で再チャレンジしたい気持ちはどこかにありました。
それとは別に、これまであまり経験してこなかった大企業の雰囲気にも興味はありました。例えば、日本の歴史ある製造業や自動車産業でDX推進を主導するといったことです。ただ、日本の大企業は興味はあったものの、風土との相性問題のリスクが大きいイメージもあり、及び腰になっていました。
なので、技術営業として日本企業にGitHubを導入してもらい、開発生産性を上げる支援をすることはバランスの取れた良いチャレンジだと捉えています。GitHub自体もMS傘下なので大企業ではありますし。
開発職ではないこと
これまで開発職ではないポジションにつくこともありましたが、いざとなれば開発に携われる立ち位置を維持しようとしていた感がありますが、今回は明確にそこからは離れることになります。
その辺りは、技術顧問等で何社か関わる中で、複数社を支援をするのも面白く感じてきたことや、Mackerel時代のハイタッチセールス的な経験がとても楽しかったことも影響しているように思います。
開発はOSS含めた趣味開発でもできます。
何者でも無くなること
今回、選考は英語での面接がほとんどで、面接官が当然ながら僕のことを知らないのが良かった。何者でもない自分をフラットに評価してくれている感じが良かった。エンプラ業界のお客様とかも僕のことは知らないだろうので、そういう中でまたフラットにスタートを切れる感じがして楽しみにしています。
英語プレゼンとk1LoW/deck
英語も多少学習は続けていたものの、まだまだ全然なので引き続きやっていきたい。
選考で英語プレゼンがあったのだけど、k1LoW/deck のおかげで資料作りが捗った。英語プレゼンだと流石にスピーカーノート無しでは無理なので、スピーカーノートを管理しやすいdeckは本当に素晴らしい。deckのおかげで乗り切れた部分は多分にあると思っているので、今年熱中して開発に取り組んで改善したモノがこのように思いも寄らぬ形で役に立ったのは面白い体験でした。
2025-12-09 11:41
この記事はPerl Advent Calendar 2025 の9日目の記事です。
さて、Cで書かれたMarkdown実装の1つであるDiscount のPerlバインディングである、Text::Markdown::Discount を sekimura さんから去年末に引き継ぎ、今年の頭からメンテナンスしていました。
ありがたいことに大本のDiscountが継続開発されていることもあって、Text::Markdown::DiscountはPerlで利用可能な最も実用的なMarkdownライブラリの1つです。このブログでも使っている拙作のブログエンジンであるRiji 内部でも使っており、私にとっても欠かせないライブラリです。
かねてから、Discount本体側のバージョンが上がるタイミングなどでsekimuraさんには度々pull requestを送っていましたが、これはメンテナンスを引き取らせてもらった方が良いのではないかと思い、昨年末にメールを送って、対応していただきました。ありがとうございました。(今メールボックスを検索したら、実は2021年にsekimuraさん側からメンテナンス移譲の打診が来ていてそれを無視していたことに気付きました…)
XS モジュールをメンテナンスするのは始めてのことなので2025年に改めてXSを学ぶ必要が出てきたのは面白く思っています。リリース周りをMinillaにしたいけどやり方に自信がなかったのですが、skajiさんが元旦に早速pull requestを送ってくれて ありがたかったです。
現在Text::Markdown::Discountをご利用の場合、ご要望やコントリビューションをいただけると嬉しいです。早速Discountバージョン3に上げる作業を滞らせてしまっていますが…。
余談
ちなみに、RubyでメジャーなMarkdownライブラリのcommonmarker はComrak というRust製のMarkdownライブラリのラッパーになっているようです。
ComarkはCommonMark互換であり、GFM拡張もオプションで実現可能というイマドキな作りになっています。私が大好きなGoのgoldmark も同様のCommonMark + GFMの構成になっているので、その辺りのバインディングライブラリをPerlで新規実装しても面白いかも知れませんね。
2025-12-03 15:14
ポッドキャストを始めるにあたり、まず配信サイトをどうするかという話があり、その辺りについての個人的見解や調査結果をまとめてみる。ポッドキャスト配信に興味がある人の参考になれば幸いです。
ポッドキャストの捉えられ方も多様になってきていますが、ここでは、特定のアプリやサイト内で独占的にしか音声を聴けないものではなく、配信者が様々なメディアに登録できて利用者が無料で利用できるオープンな形式のものを指すこととします。そちらの方が広くリーチしたい場合には効果的でしょう。
メイン配信プラットフォーム選定
大本の配信元をどこにするか。これは、以下の分類になる。ただ、何れのパターンを選ぶにせよ、Spotifyへの登録はお勧めする。(後述)
Spotify が無難。特に企業でやるなら
シェアが大きい
担当者も前提知識少なく始められる
分析機能も見やすい
個人でやるならLISTEN もオススメ
コミュニティ要素が上手く機能している
文字起こしが最初から全てのポッドキャストで有効にできる
エンジニアだったら自前構築もオススメしたい
私の場合、趣味でOSSをやっている者だ 、はPodbardによる自前構築でCloudflare上でホストしている。ヘンリー理想駆動ラジオ はSpotifyだ。
個人的には自前構築を推している。何れのパターンにせよ、最終的には複数媒体に登録することになるので、どこが「ホームページ」なのかが分かりづらくなって分散してしまう問題があるが、自前構築であれば大本のサイトがホームページであることが明確になる。Spotifyをメインにしている場合も、別途ホームページを設けているパターンも見る。
また、プラットフォームの番組画面をホームページにする場合には表現の自由度が低いのも難点。Spotifyだと、概要欄や説明欄のテキストエリアが使いづらい。一応、Spotifyの説明欄にはHTMLを直接記述できるので、私は、Markdownで書いてローカルでHTMLに変換した物をテキストエリアに貼り付けている。
余談だが、自前構築をやりやすくするために作ったOSSがPodbardであり、個人的には満足できる出来になっているが、全然使われていないのが残念。この領域ではYattecastが古くからが人気で数多くのポッドキャストが利用している。Podbardにも後発の強みがあると思っているが、やはり、Yattecastの凄さを改めて感じる。Podbard使いたい方はお知らせ下さい。今なら篤くサポートします。
アートワーク画像の準備
ポッドキャスト番組には、各媒体でアートワーク画像が求められる。媒体ごとに若干指定が異なるが、基本的には正方形のJPG画像であるため、1400x1400 pxの画像を一個用意しておけば使い回ししやすいだろう。画像の作成は、趣味活動であれば生成AIに作らせるのも今ならお手軽だ。
各プラットフォームへの登録
ポッドキャストを始めるまで知らなかったが、リスナーが利用するポッドキャスト媒体は今やSpotifyがトップで、リスナーの1/3程度が利用している。最低限Apple Podcastに登録しておくかと思っていたが、最低限登録するなら今やSpotifyが最優先だ。また、Amazon Music + Audibleも侮れないシェアがある。YouTubeもやった方がよいだろう。
この辺のリサーチについては、オトナル・朝日新聞社が出している、ポッドキャスト国内利用実態調査が参考になる。2024年と2025年でガラッと傾向が変わっているところがあるのも面白い。2025年の調査ではYouTubeが視聴メディアでトップになった。このあたりは「ポッドキャスト」に対する認知や解釈が広がってきたことが影響しているのだと思う。
登録推奨プラットフォーム
上記を踏まえ、以下のプラットフォームへの登録をお勧めする。全て無料で出来て登録も簡単だ。プラットフォーマー的にはコンテンツが増える分には歓迎というのがあるのでしょう。
Spotify
Apple Podcast
Amazon Music
YouTube
LISTEN
何れも、RSSフィードのURLとアートワーク画像を用意しておいて、それぞれにアカウント登録してフォームを適宜埋めて申請すれば、しばらくすればそれぞれの媒体上にラインナップされる。ちなみにYouTubeは「趣味で〜」の場合何故か3ヶ月くらいかかった。
各種プラットフォームに登録すると、それらの管理機能を使えるのも嬉しいポイントだ。例えば、Spotifyのアクセス解析やLISTENの文字起こしなどは個人的に有用だった。Spotifyのアクセス解析はSpotifyをメインにしていないとSpotify経由のものしか取れないが、それでも傾向を見るには十分だ。
ちなみに、複数プラットフォーム登録による難点として「コメント分散問題」というのがあるようだが、残念ながら私はそれには困っていない。
RSSフィードの確認
各種プラットフォームに登録する為にはRSSフィードというやつが必要になる。Spotifyの場合RSSフィードが有効になっているか確認して、そのURLを控えておこう。
あなたのRSSフィード - Spotify
このRSSフィードがあれば特定の媒体に限らず、他のプラットフォームやポッドキャストクライアントで聴いてもらえるので、大事です。
ホームページ / 公式サイト
付随要素ではあるが、ポッドキャストのホームページがあると嬉しい。お知らせや各種リンクをまとめて置く場所は欲しくなる。自前構築であればそこをホームページにできるが、プラットフォーム上で配信している場合には、追加で別に用意することになる。独自ドメインがあると嬉しいが、どこまで凝るかとの兼ね合いではある。
シンプルなリンク集で大体事足りるので、プロフィール作成サイトの利用をよく見かける。具体的には Bento が身の回りでは多い印象です。
また、メルマガサブスクなどで使われるSubstack をほっとテック ではホームページとして使っていて、これはおしゃれだと思う。無料で使えて、独自ドメインも割り当てられる。こういうサービスは一般的には独自ドメインを利用する為には有料プランの継続利用が必要になることが殆どだが、Substackはワンショットの$50で独自ドメイン設定ができる ようなので良心的。ちなみに、ほっとテックの場合はまた別の方法で実現しているようです。
独自ドメインを使った番組サイト・ニュースレター配信の設定 - ほっとテック Newsletter 準備号
ちなみにSubstack自体にもポッドキャスト機能がある ことに今気付きました。
ホームページに何を載せるか
各プラットフォームへの番組リンクの他、以下のような要素が多く見られます。お好みで用意して載せると良いでしょう。
お便りフォーム
公式SNSアカウント
コミュニティ
まとめ
ちゃんとやろうとすると何気に色々用意する物が出てきてしまいますが、興味があれば、まずは最低限パッと始めてみてはどうでしょうか。気が向いた時に後から整えれば良いのです。
例えば、LISTENであれば、アカウント登録と番組登録をして、ブラウザから録音するだけ。何も用意せず、無料ですぐに始められます。LISTENでは声日記 という気軽な音声配信ムーブメントが生まれているのも面白いところです。
「趣味でOSSをやっている者だ」は自前構築でやっていて、Cloudflare でホストしていますが激安なのでほぼお金はかかっていません。独自ドメイン代はかかっていますが、それもオプショナルなものです。なので何れにせよポッドキャストを運営する際には、配信面ではほとんどお金はかかりません。
機材や収録環境、編集などは、お金をかければキリがない世界でもありますが、逆に安く抑える方法もあります。手持ちのスマホだけで追加コスト無しで始めることだってできます。私がどうしているかは、以下を参考にしてみてください。